
Python Web 内存调优,以及 Python 中的 Copy-on-Write
最近把所有服务迁移到 Kubernetes 之后,终于可以直观地通过可视化面板观察容器的资源使用情况了。在看的时候发现自己写的 Python Web 项目一启动就要占用 250MB 左右内存,感觉有点偏高,于是尝试优化。这篇文章牵涉到 Linux 的 CoW 在 Python 中的处理方式,目前中文互联网上没有什么资料,于是我顺便填补一下这个空白。
最近把所有服务迁移到 Kubernetes 之后,终于可以直观地通过可视化面板观察容器的资源使用情况了。在看的时候发现自己写的 Python Web 项目一启动就要占用 250MB 左右内存,感觉有点偏高,于是尝试优化。这篇文章牵涉到 Linux 的 CoW 在 Python 中的处理方式,目前中文互联网上没有什么资料,于是我顺便填补一下这个空白。
lazy-apps 选项
uWSGI 有一个选项叫做 lazy-apps,它控制的是加载 WSGI app 和 fork () 系统调用的先后顺序。当 lazy-apps 为 true 时,先 fork () 再在每个子进程里加载 app;反之,先在 master 进程里加载 app 再 fork ()。显然,加载一次 app 再 fork () 可以让子进程之间共享更多的内存。
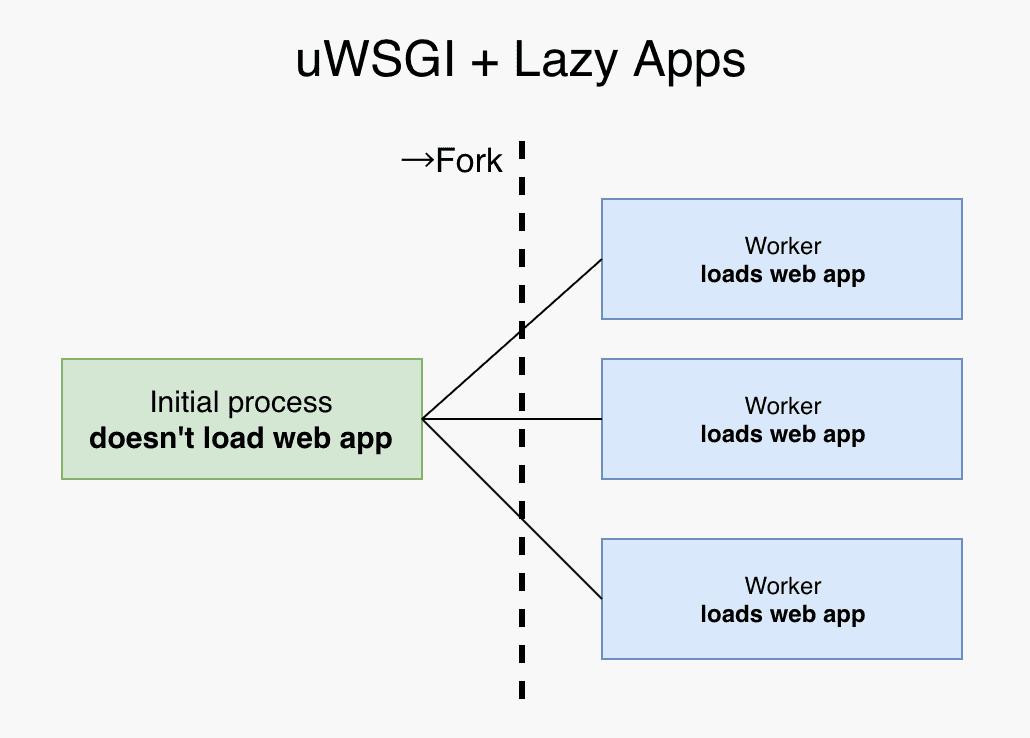
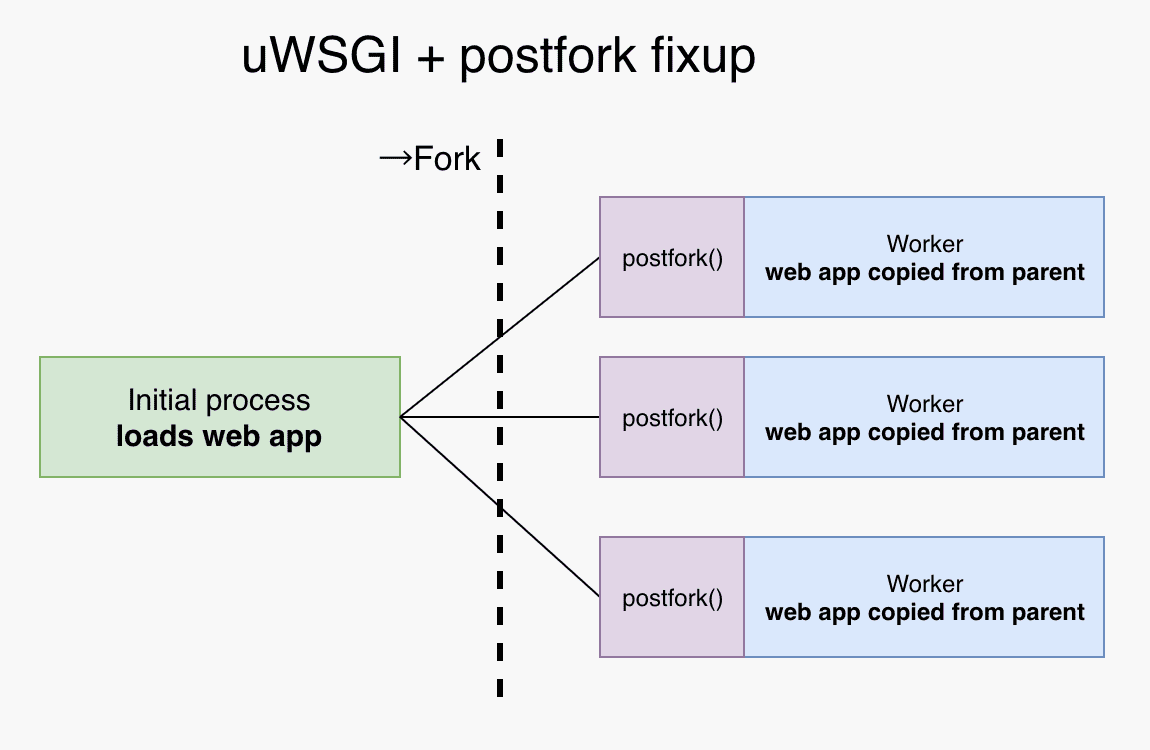
需要注意的是,通过这种方式共享内存并不总是安全的。举个例子,如果你的程序在启动时启动了后台线程用于处理异步任务,并通过队列在 worker 进程中添加任务,你可能会遇到问题。fork () 并不会为每个 worker 创建单独的后台线程,所以队列变成了只有生产者、没有消费者。我们需要通过 uwsgidecorators.postfork 装饰器为每个 worker 进程进行一些修补。
延伸阅读:关于 lazy-apps ,这篇文章值得参考:https://engineering.ticketea.com/uwsgi-preforking-lazy-apps/ (上面两幅图片的来源)。
动态产生 workers
如果你的流量波动比较大,你可能会希望在平时使用较少的 worker 数,而在流量增加时自动增加 worker 数。uWSGI 的 cheap 功能可以做到这点。以下是一个使用示例:
processes = 6
cheaper = 3
cheaper-algo = backlog其中,processes 代表最大的 worker 数,cheaper 代表最小的 worker 数,cheaper-algo 是判断是否需要增加 worker 数的算法,具体可以参看官方文档: https://uwsgi-docs.readthedocs.io/en/latest/Cheaper.html 。
Python 中的 Copy-on-Write
Instagram 作为可能是世界上最大规模的(基于 django 的) Python Web 项目,在内存优化方面有不少尝试。我参看了他们的几篇文章:
提炼一下重点:
Linux 的 Copy-on-Write (写时复制)是一个给 fork 出的进程提供的优化机制。子进程在启动时会与父进程分享每一个内存页,当子进程尝试写入时,内存页会被复制到子进程的内存空间,而读是无需复制的。然而在 Python 的世界中,Copy-on-Write 却退化成了 Copy-on-Read:
由于对象的引用计数(引用计数是为了垃圾回收),每当我们读一个 Python 对象时,解释器会增加对象的引用计数,这就导致了对底层数据结构的改变,于是产生了 CoW,这就变成了 “读时复制”。
#define PyObject_HEAD \
_PyObject_HEAD_EXTRA \
Py_ssize_t ob_refcnt; \
struct _typeobject *ob_type;
...
typedef struct _object {
PyObject_HEAD
} PyObject;
更加不幸的是,即使是不可变的对象,比如代码(PyCodeObject)也是 PyObject 的 “子类”。所以也会有 “读时复制”。
除此之外,垃圾回收(GC)机制会使用链表将对象连接起来,在进行垃圾回收时,链表会被打乱。因为链表的结构(像引用计数一样)也存储在对象的数据结构中,打乱链表中的对象也会导致页面被 CoW。
考虑到 GC 时被 CoW 的问题仅存在于 master 中创建然后被 workers 共享的对象中,Instagram 团队尝试让这些共享的对象对 GC 机制不可见。 他们在 Python 的 GC 模块中加入了 gc.freeze () 方法,将对象从 Python 内部维护的用于垃圾回收的链表中去除,并将这一更新推送到了 Python 社区(https://github.com/python/cpython/pull/3705 )。这一 API 将在 Python 3.7 之后可用。
调整垃圾回收
那么,我们开始进行实际操作吧。
首先升级到 Python 3.7,然后查看 gc.freeze () 的用法:
Freeze all the objects tracked by gc - move them to a permanent generation and ignore all the future collections. This can be used before a POSIX fork() call to make the gc copy-on-write friendly or to speed up collection. Also collection before a POSIX fork() call may free pages for future allocation which can cause copy-on-write too so it’s advised to disable gc in master process and freeze before fork and enable gc in child process.
于是在我们程序的入口:
import gc
from server import create_app
app = create_app()
# disable gc and freeze
gc.set_threshold(0)
gc.freeze()
然后在子进程中开启 GC:
import uwsgidecorators
@uwsgidecorators.postfork
def enable_gc():
"""enable garbage collection"""
gc.set_threshold(700)
结论
在这篇文章中我们谈到了 CoW 机制在 Python 中的特殊性,并通过 Python 3.7 的新 API 对程序进行优化。效果有待进一步检验。